Step 2: Specify Import Parameters
Specify the CSV Identity Mode and the CSV Identity Mode by clicking on one of the radio buttons:
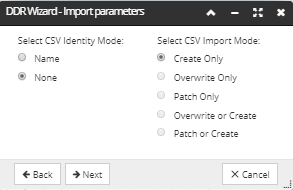
NOTE: Successful matching is critical in order to do updates of existing objects and to avoid creating duplicated objects.
Setting the CSV Identity value specifies how the data from the CSV records is matched against existing IRM objects. The following identity modes are supported:
|
Identity Mode
|
Description
|
|
Name
|
The CSV data must have a column mapped to the IRM name field. If not, the server returns an error. All Import Mode values are possible.
|
|
None
|
This means there is no attempt to match the CSV records against existing IRM objects. The only valid Import Mode is Create Only
|
Setting the CSV Import value specifies whether new objects are created from the CSV data or existing IRM objects are overwritten by matching CSV objects. The following import modes are supported:
|
Import Mode
|
Description
|
|
Create Only
|
If Identity Mode is None, the server creates a new IRM object for every CSV record. Otherwise, the Identity Mode and corresponding column data are used for each row to determine whether there is a matching IRM object. If there is, the CSV record is ignored, otherwise a new IRM object is created.
|
|
Overwrite Only
|
If the server can find a matching IRM object by using the Identity Mode and corresponding column data for each row, it updates all of the object, using whatever mapped fields are available from the CSV data, and default values for the rest of the fields. Otherwise, the CSV row is ignored.
|
|
Patch Only
|
If the server can find a matching IRM object by using the Identity Mode and corresponding column data for each row, it updates that object from the CSV data with any mapped fields and other fields are left unchanged. Otherwise, the CSV row is ignored.
|
|
Overwrite or Create
|
If the server can find a matching IRM object by using the Identity Mode and corresponding column data for each row, it updates all of the object, using whatever mapped fields are available from the CSV data, and default values for the rest. Otherwise, it creates a new object from the CSV data.
|
|
Patch or Create
|
If the server can find a matching IRM object by using the Identity Mode and corresponding column data for each row, it updates that object from the CSV data with any mapped fields. Otherwise, it creates a new object from the CSV data.
|
IMPORTANT: The difference between Overwrite and Patch is that Overwrite updates the entire target object, whereas Patch only updates the fields explicitly supplied in the CSV file. In most cases, the Patch modes are more appropriate.
Click on the  checkbox to set the lookup of Reference objects by their Alternate Name field (if they have one) in case a name is used in the CSV data.
checkbox to set the lookup of Reference objects by their Alternate Name field (if they have one) in case a name is used in the CSV data.
For reference fields, either single references or lists of references (e.g. Vendors), the CSV data can contain either IDs as small integers or names. Which is used can even vary on a row-by-row basis. If a name is used in the CSV data, the server will look for the matching object by its Name parameter, unless Prefer Alternate Name For References is true and the relevant object type has an Alternate Name field. For example, if this value is true and the server is trying to locate an object to fulfill the Vendors reference, then Alternate Name will be used.
Click on the Next button on the bottom of the dialog to proceed with the next step of the DDR Import wizard - 