4.5.1. Proxies, Correlation, and Discovery Data
Below are some definitions and terminology commonly used through this and the following sections:
-
Data Source is the enumeration of all IRM components and third-party products that can generate IRM objects. Each object has a Data Source field assigned to track what generated the object.
-
A Proxy Source is an abstraction for a special kind of Data Source that supports generating Proxy objects, which in turn represent objects in some external system. Proxy Source also contains a Data Source field, and the name of the Proxy Source matches the name of the Proxy Source's Data Source.
-
An Integration Service is a separately licensed IRM component that integrates IRM with one or more third party products. For some, the associated Integration Service has its own Data Source and Proxy Source. For BMC, however, a single Discovery Integration Service is used for multiple purposes, including BMC integration and generic discovery operations.
IRM supports the integration of data from various discovery tools, such as BMC.
When a Discovery Set (set of data from a discovery tool) is imported, IRM creates a Proxy for each external object then tries to find a corresponding IRM object that matches the external object, using a correlation strategy. If the correlation is successful the Proxy and the IRM object are given references to each other, facilitating further synchronization operations.
Proxies have their own Super Category and the following properties:
-
A Proxy is a general representation of an object that exists in some external system.
-
Proxies can exist for both instance and Type objects.
-
A Proxy is also a Categorized object (like Locations, Maintenance Holes, Users, Contracts, etc.) Proxy Categories appear in the appropriate Super Category in the C&T Tree:
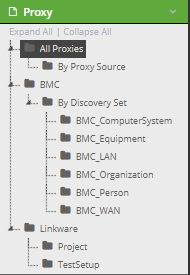
-
A Proxy contains additional information about the originating discovery engine, time of discovery, etc.
-
A Proxy has very few semantic fields, while the external data coming from a discovery engine is stored as non-semantic fields, which are assigned through a parent Category.
-
Proxies have their own tab in the Object Grid:
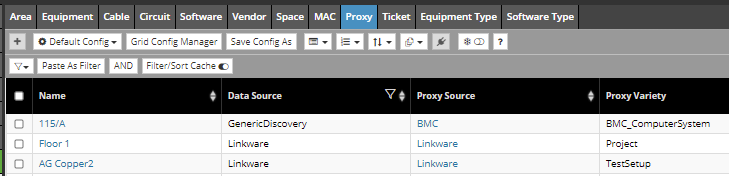
Proxy Source objects contain data the server needs to know about each source of Proxy objects, so that various operations can be handled on the server side; a Proxy Source is a configuration object used by an Integration Service. One key field is a mapping table called Field Aliases, or Field Map, that gives the mapping between an external field (e.g. "Asset Name") to one of IRM's built-in fields, either semantic or non-semantic.
Click on the following link for detailed information on configuring Proxy Source object for BMC.
If a correlation is attempted but no matching IRM object exists the correlation will fail - this kind of non-correlated Proxy is a candidate for creating a matching IRM object (sometimes called a "twin"). If an IRM twin is created (by the user), the fields indicated by the Field Aliases are copied. Also, the Data Source of that twin is set to the same value as the Proxy’s Data Source.
In summary, IRM operations related to discovery data can be broken down into the following steps:
-
Proxies are created by an Integration Service, from a discovery engine or other external data source.
-
Proxies are correlated to some IRM object and/or other Proxies.
-
Proxies are shown in the user interface, used for reporting, and allow direct linking between IRM objects and the corresponding objects in external systems.